Im going to break down how the clustering works on a small dataset. This is taken from a Machine Learning 101 session we did with Data Plus Women last year. It was a great session with Nitika Sharma so full credit goes to her work.
The Data
Lets take a look at the data and how it looks plotted. Taking a look at the visualiation, its pretty clear to me there are 2 clusters we want to draw out of the data. A+B could be 1 cluster and Points C+D should be another.
|
Point
|
X2
|
Y2
|
|
A
|
1
|
1
|
|
B
|
2
|
1
|
|
C
|
4
|
3
|
|
D
|
5
|
4
|
How does it work?
So lets assume you know that you want to find 2 clusters. How does it figure out what should be in those clusters? Once I explain this, you’ll feel like this probably could be more impressive- in fact you might have the impression like me that it was done with brute force!
It sets 2 centroids, so it’ll take 2 datapoints as its centroids. Then calculate the distance with pythagorian distance. Literally every point with every centroid. So in a dataset of 4 points, thats 8 calcs. then you assign each datapoint to the centroid with the smallest distance.
The Calculations
Lets use (1,1) + (2,1) as our centroids. Its arbitrary but it gives us a start. That means our data will start like this: Theres a lot of redundancy in the table– the original data table on the left is repeated twice and the centroids themselves are repeating along the rows.
|
Centroid 1
|
|||||
|
Point
|
X2
|
Y2
|
X1
|
Y1
|
|
|
A
|
1
|
1
|
1
|
1
|
|
|
B
|
2
|
1
|
1
|
1
|
|
|
C
|
4
|
3
|
1
|
1
|
|
|
D
|
5
|
4
|
1
|
1
|
|
|
Point
|
X2
|
Y2
|
Centroid 2
|
||
|
A
|
1
|
1
|
2
|
1
|
|
|
B
|
2
|
1
|
2
|
1
|
|
|
C
|
4
|
3
|
2
|
1
|
|
|
D
|
5
|
4
|
2
|
1
|
|
But this format allows us to really clearly see the following mathematical operations:
1) Finding the difference from the centroids 2) Squaring these differences 3) Adding the squares 4) finding the square root.
|
Step 1
|
Step 2
|
Step 3
|
Step 4
|
||||||||
|
Centroid Points
|
Centroid
|
Find the difference
|
Square the difference
|
Add the squares
|
Find the square root
|
||||||
|
1
|
1
|
Centre 1
|
0
|
0
|
0
|
0
|
0
|
0
|
|||
|
1
|
1
|
Centre 1
|
1
|
0
|
1
|
0
|
1
|
1
|
|||
|
1
|
1
|
Centre 1
|
3
|
2
|
9
|
4
|
13
|
3.605551275
|
|||
|
1
|
1
|
Centre 1
|
4
|
3
|
16
|
9
|
25
|
5
|
|||
|
2
|
1
|
Centre 2
|
0
|
0
|
0
|
0
|
0
|
0
|
|||
|
2
|
1
|
Centre 2
|
0
|
0
|
0
|
0
|
0
|
0
|
|||
|
2
|
1
|
Centre 2
|
2
|
2
|
4
|
4
|
8
|
2.828427125
|
|||
|
2
|
1
|
Centre 2
|
3
|
3
|
9
|
9
|
18
|
4.242640687
|
|||
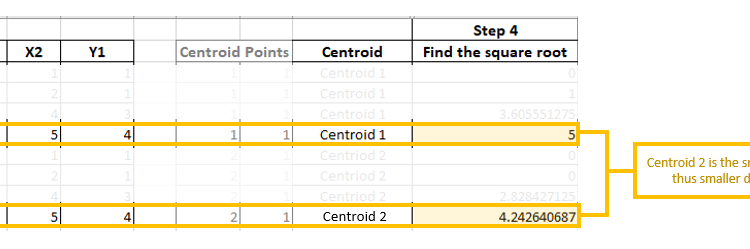
Each point gets assigned to a centroid based on the distance between the points and the centroids. Like so!
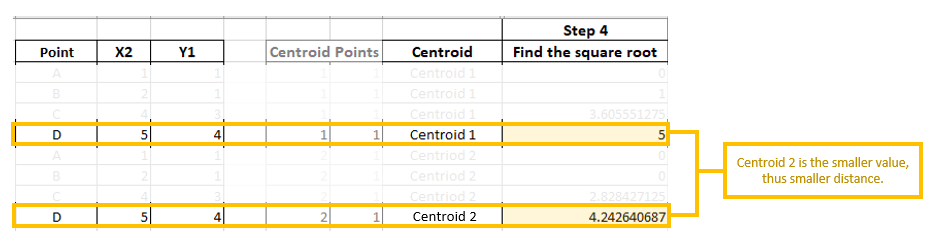
In this case, Points B, C, D are assigned to Centroid 2 and Point A to Centroid 1.
When Do New Assignments Form?
From here, we want to find the NEW centre. After all, we’ve kind of found 1 cluster. But if we redid this process again, will we gain the same results? This is the true test of if they are the clusters we are looking for! To do this, we compute new centroids based on the average of each of our new clusters– that is the average of B, C, D (the points assigned to centroid 2) and of Point A (centroid 1).
|
Step 2
|
Compute new centroids (only centroid 2 here)
|
||
|
B
|
2
|
1
|
|
|
C
|
4
|
3
|
|
|
D
|
5
|
4
|
|
|
New centroid is the average
|
3.6667
|
2.6666667
|
|
Then we do the distance calculation all over again. But notice here that in Point B, the distance is closest to Centroid 1. So actually Point B has be reassigned to Centroid 1! I’ve left out Point A here but the interesting part is happening in Point B. Point A will continue to stay assigned to Centroid 1.
|
Find the square root
|
|||||||
|
Point
|
X2
|
Y2
|
X1
|
Y1
|
|||
|
B
|
2
|
1
|
Centroid 2
|
3.666667
|
2.6667
|
2.357022604
|
|
|
C
|
4
|
3
|
Centroid 2
|
3.666667
|
2.6667
|
0.471404521
|
|
|
D
|
5
|
4
|
Centroid 2
|
3.666667
|
2.6667
|
1.885618083
|
|
|
B
|
2
|
1
|
Centroid 1
|
1
|
1
|
1
|
|
|
C
|
4
|
3
|
Centroid 1
|
1
|
1
|
3.605551275
|
|
|
D
|
5
|
4
|
Centroid 1
|
1
|
1
|
5
|
When Does it Stop?
Then you repeat this process above until the assignments stop changing.
Final Thoughts
…and that is clustering on a small dataset! Thank goodness we have computers because when you think about it, its super annoying to have to do this for each new measure, and to check when the reassignments stop changing.
I really enjoy breaking down concepts like these with small datasets because it allows for myself to have a deeper set of knowledge without nearly as much confusion. Hope you enjoyed it too!